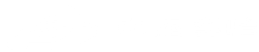生理特征比较稳定、生来不变,能够准确地反映身份。而行为特征在交互的过程中体现身份,貌似不是特别稳定,不太适合身份认证。
 清华大学语音和语言技术中心主任郑方
清华大学语音和语言技术中心主任郑方
在大数据、人工智能时代,语音识别和声纹识别作为非常重要的技术手段,成为我们主要的关注点之一。在第二届“大数据在清华”高峰论坛“语音处理及数据安全技术专场”中,清华大学语音和语言技术中心主任郑方发表题为“语音技术与身份信息的隐私保护”的演讲,探讨了中间身份信息隐私保护的问题,以及语音处理技术在其中发挥的重要作用。
郑方:在互联网时代,人们的生活既存在于物理空间,又存在于网络空间,其中网络空间的安全问题非常关键。世界各国就如何在网络空间里进行身份认证问题,提出了很多的计划,以推动个人和组织在网络上使用安全、高效、易用的身份解决方案。
在这些身份认证方式里面,未来的主体方案就是生物特征识别技术。生物特征分为两类:
一类是生理特征,如指纹、人脸、虹膜、掌纹、指静脉,包括DNA等;
另外一类是行为特征,以交互的行为来进行身份认证,如声纹、签名、步态、手势以及键盘的敲击等。
生理特征比较稳定、生来不变,能够准确地反映身份。而行为特征在交互的过程中体现身份,貌似不是特别稳定,不太适合身份认证。
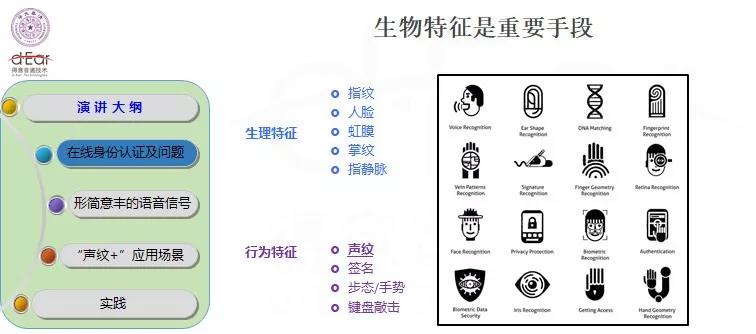
在生物特征识别技术的发展过程中,人们面临着诸多安全问题,如利用他人照片、视频,即可对人脸识别系统轻易进行攻击,或者只需采用一些传统方法,就可以轻易攻击某些基于AI安全手段的系统。这些问题导致的原因大概分为以下四个方面:
算法的准确率
算法漏洞
成本因素:由于不能提供更多的传感器,如不能进行三维的图像,往往是用二维的,或者是用简单的传感器来采集人脸图像,因此防攻技能降低,这里不管是硬件成本,或者是技术成本都是采用低成本方案。
生物特征内在的因素:在现在技术条件下,生理特征的不变特性,使得用人工智能技术就可以把各种不变的东西完全造出来,如指纹可以通过指膜实现,虹膜可以通过一个假的隐形眼镜实现。
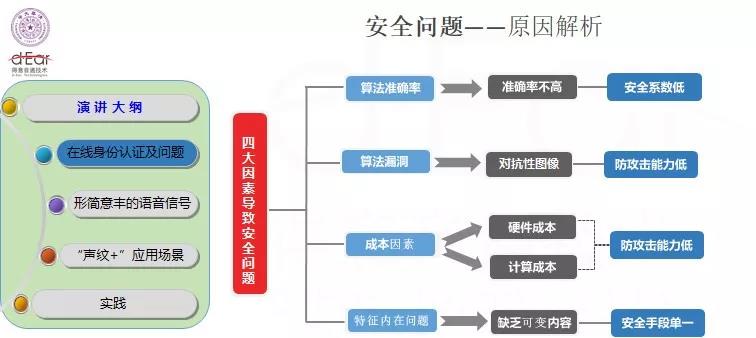
由于生理特征的不可撤销性,信息在采集和传输的过程中可能丢失,信息丢失之后整个人的身份就丢了;而后这些信息可能在任何的时候被非法使用,这就是隐私丢失对安全的冲击。安全和隐私,是一对孪生兄弟,它们是无监督的身份认证必须考虑的问题。
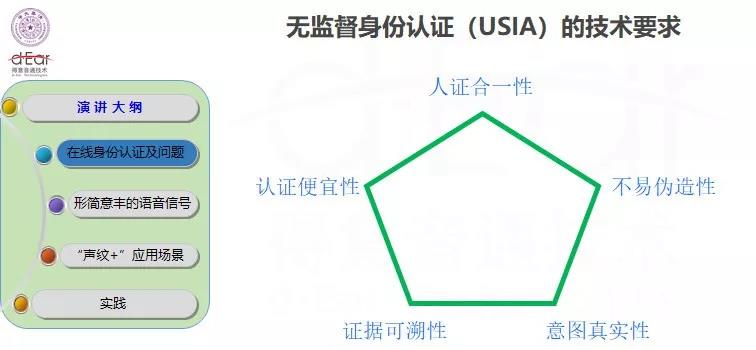
在无监督的情况下,如何安全地进行身份认证是非常关键的。将生物特征用在无监督情况下的认证,要考虑以下五个方面的因素:
人证合一:生物特征要具有唯一性,识别技术要能够保证准确性。
不易伪造:活体检测可用于防攻击,而且性价比高。
真实意图:被认证的真实意图不怕丢失和复制,可保护隐私,但比活体检测更难、更为需要,因为它包含了活体检测的功能。
证据可追溯:在无监督的情况下,每一次的认证能记录证据,就可用于追溯。
认证的便(pian)宜和便(bian)宜:所谓便宜就是成本低,便宜就是方便,设备、平台依赖性低,使用方便。
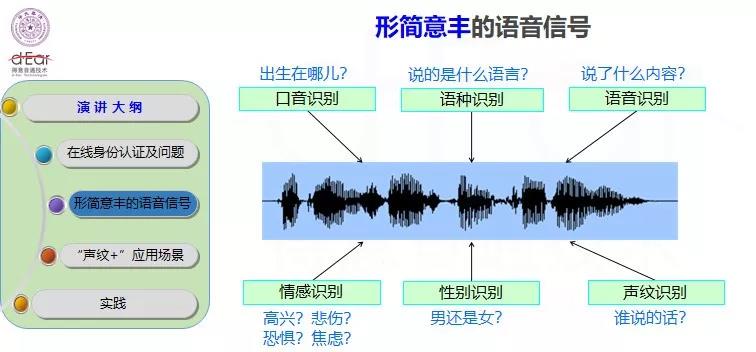
语音信号可以在很大程度上解决这一问题。语音信号是一个形简意丰的信号,信息量很大,比如说口音、语种、情感、性别身份和语音的内容,各种的信息都在一维的信号里面表现出来。
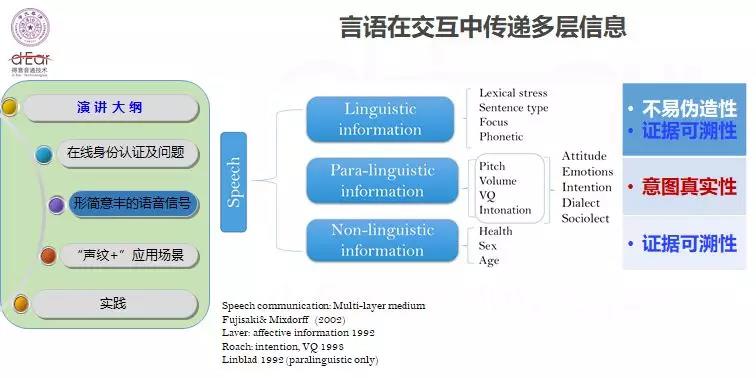
从结构化角度,人类的语言信息可以分为三层:
第一层是语言信息,包括语音内容和语句;
第二层是副语言信息,包含说话人的态度、情感、意图等等,体现为音高、韵律、音量、音色,还有语调等,可以展现意图和态度;
第三层是非语言信息,如身体状况、年龄、性别。语言信息有利于防止伪造,也有利于保存活的证据;副语言信息有利于检测真实意图,非语言信息可部分地追溯证据。
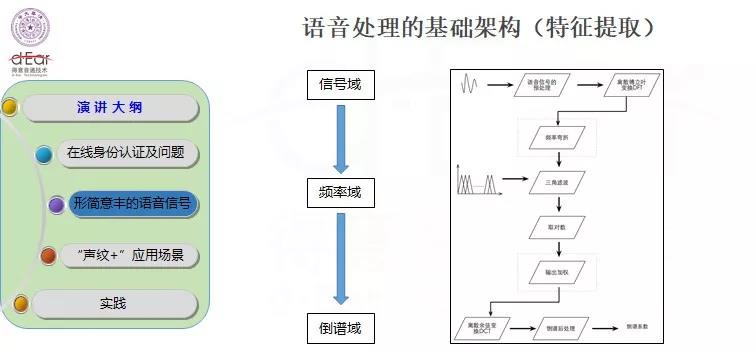
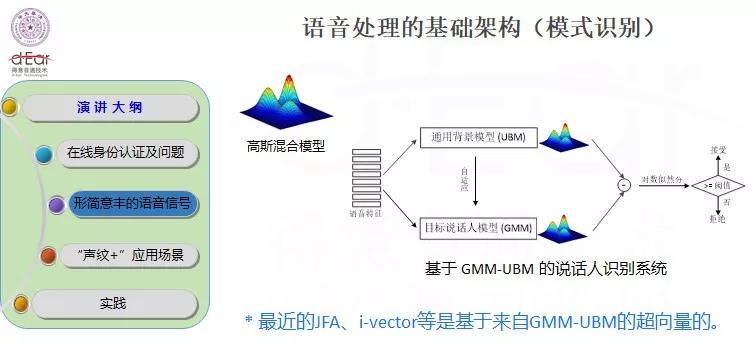
随着深度机器学习在语音识别、图像处理等领域的快速发展和成功应用,近年来,基于深度学习的相关方法也逐渐应用到说话人的识别中,并取得了不俗的成效。声纹识别首先涉及的是特征提取。现在用得比较多的特征提取是MFCC,一种倒谱参数,它的参数提取涉及了多层,不是在信号域提取特征,找到一些特征点和模板,而是要把它先变换到频谱域,再变换到倒谱域,经过三层的操作得出一个特征。
但是这个特征还不够,需要继续做模式识别,我们采用的模型,里面有对混合、高斯的分布进行描述,最后由通用背景和GMM的共同作用,对说话人进行刻画,最后进行身份认证。
若要安全地进行身份认证,对声纹的第一要求就是人证合一性。相比其他生物特征,声纹的性能比人们了解的要高。在几种生物特征里面,识别准确率依次为虹膜、声音、掌纹、指纹、指静脉、人脸。
第二个是不易伪造,声音有比较好的防攻击优势。语音都可以用软件手段来防攻击,首先利用语音的形简意丰的特点,要识别出“谁说了什么”。其次,如果攻击者把声音录下来,然后进行拼接,我们可以进行录音重放检测。另外,可以把人的因素加进去,“三分技术七分管理”,用户自定义的数字读音和动态密码组合,形成奇妙的不用记忆的“密码”,这也是最安全的密码。
此外,可以把多特征、多活体做结合。这里用的是嘴唇,嘴唇本身有身份的信息,加上声纹就是双身份。唇语跟语音的内容一样,时序一样,这就是更强的活体检测,更能防止攻击。
第三个是检测意图的真实性,比如语音的识别,以确定是否在无意识状态下被使用;情感识别,以确定是否受到胁迫;语音理解,以确定是否传递不便明说的危险状态。
第四是证据可追溯,语音识别记录要求回应的随机内容,含有时间和场景的烙印;非语言信息可提取年龄、健康、环境等信息,含有辅助的时间和场景的烙印,都可以帮助证据。
最后一个特点认证的便(pian)宜性和便(bian)宜性。麦克风或传感器的成本超低,传输带宽窄;而语言是人类交流最自然的方式,也没有跨平台的问题。
当然若加上更多的特征,会是最好的解决方案。“声纹+”具备更高安全、更低成本、更低隐私的特点。
“声纹+”有很多应用场景,如系统的登陆、用户的交易、线上反欺诈、门禁和考勤等等。利用语音的特点,可以做到一句话解决所有问题。通过声纹识别对我们说的一句话进行身份认证,通过语音识别进行指令的理解,通过情感识别进行意图理解,可知道真实意图,最后解决所有问题。
通过清华语音和语言技术中心的知识产权入股公司以及共同成立联合实验室等合作模式,我们围绕声纹识别做申请了很多专利,分别从不同的方面解决问题。对于未来构想,我们想做到随时随地的身份认证,包括汽车、旅馆、无人商店、ATM等任何地方。
现在声纹识别技术已经到了一个奇点,2018年就是声纹的元年。通过声音做身份认证可以解决很多问题,未来的生活将更为便捷。