9月底轰动业界的史上最强GAN,也就是最高动用512个TPU训练的BigGAN,Demo已经正式放出!
只要一台能上网的电脑,你就能用它生成各种各样的逼真图片。
体会如何让非洲鳄完美渐变成胖达~
这意味着,不用花10-70万元的费用租TPU亲手训练,只要打开DeepMind放出的地址,就可以体验到亲手支配BigGAN的感觉。
BigGAN Demo体验攻略
DeepMind官方给出了128、256、512三种尺寸的Demo。
不过无论你打开哪一个,Colab里默认的都是256的Demo,其他尺寸要手动自行调整。
预先设置
打开之后,保证网络已连接,然后把每个代码块挨个运行一遍。
首先,设置模块路径为https://tfhub.dev/deepmind/biggan-256/1
然后完成一系列设置,召唤TensorFlow。
之后从TF Hub加载BigGAN模型。
定义一些用于采样和显示BigGAN图像的功能。
创建TensorFlow会话,初始化变量。
单样本生成
完成这些准备工作之后,我们就可以正式开始玩BigGAN了。
界面上有4个设置选项,先看最后一个category,用来选择生成的东西是什么,下拉菜单里一共有999个品种可供选择,我们就用默认的933号品种芝士汉堡来试一下。
前面的三个选项是生成的具体参数,第一个num_samples是生成汉堡的数量,可以从1~20的范围内随意调节。
第二个truncation可以在0~1之间调整,数字越小,图形越整齐划一,造型保守;
数字越大,图形之间的差距越大,经常能生成完全和汉堡没关系的图像。
第三个noise_seed,噪音种子,可以在0~100之间调节,这个数值越大,汉堡造型越狂野。
Cheeseburger is laughing at U~
物体渐变
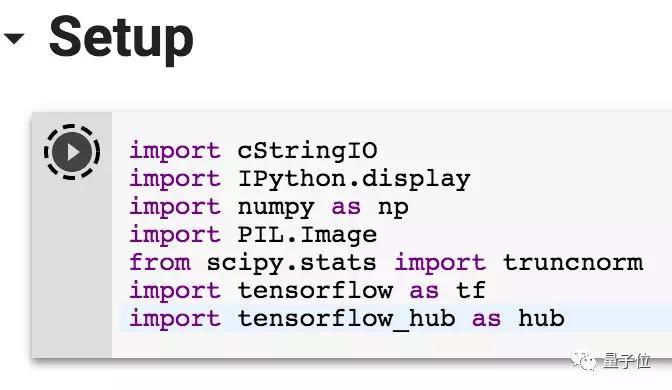
学会生成单只汉堡以后,就可以尝试第二个功能:物体渐变,学名Interpolate between BigGAN samples.
物体渐变嘛,顾名思义,把一个物体渐变成另一个物体。
当然,因为涉及两个物体,需要设置的内容也多了一些。
我们先来选择两个物体:
物体A(category_A):金毛狗。
物体B(category_B):小金鱼。
两个物体可以分别调整noise_seed。
每个生成结果都长这样,每一行是从金毛到金鱼的渐变过程,行数则是样本数量,也就是生成几条渐变。
开头的第一个设置num_samples,就是“行数”,物体渐变条的数量,可以从1~5之间选择;
下一个设置选项num_interps指的是每个渐变过程的“帧数”,“帧数”越大,渐变过程越详细,最小可以设置为2,最大可以到10;
另外同样可以设置truncation,和前面的单样本生成一样,truncation越大,不同样本之间的差距就越大。
好了,具体操作就这些,大家可以自行在文末寻找传送门亲自体验~
另外,还有热心群众做了一个gif版,可以自动把物体渐变的过程变成gif,效果大概就是下面这样:
同样文末可找到传送门。
贵!贵!贵
此Demo一出,国外人民纷纷发来贺电,有表示效果震惊的,有想玩拍手叫好的,也有……看饿了的。
谷歌大脑东京研究员、推特知名科技网红hardmaru就评价说,选择用哪个GAN,怎么跟从快餐汉堡菜单中点餐似的。
推特网友-=CULLEN也表示生成的食物实在有些过于逼真,认认真真看个学术研究怎么一下子就饿了。
有网友认为BigGAN在设计行业潜力无穷,它的风格转换以及材料和设计的多样化组合对设计师具有指导意义。
这位网友还抱着试一试的心态用Demo生成各种包,发现这个效果有点惊人啊。
也有网友顺势而为,企图再加一份饭。“恭喜!这项工作真的难以置信,很喜欢实验中失败图像的细节……所以如果能放出代码,社区会更加感谢。”网友elder_price666说。
不过大哥留步,想训练一个自己的BigGAN?请先三思能不能负担起训练需要消耗的资源啊。
很可能就算官方给了TensorFlow实现和代码,你也要不起啊!
根据论文附录中提供的细节,BigGAN是在TPU Pod上训练出来的。训练一个生成128×128图像的BigGAN模型,要用128个Google TPU 核心。256×256、512×512模型需要的TPU核心数也相应上涨到了256个和512个。
更惊悚的是,用了这么多TPU的情况下,大部分模型还要训练24到48小时,也就是要等上一两天才能见到成品。
按照Cloud TPU v2每TPU每小时4.5美元的价格来算,训练一个基础版128×128的BigGAN,也就是最最最低配的那个,需要1.38万美元到2.76万美元,折合人民币9.6万元到19.3万元。
至于512×512的高清大GAN,训练费用最高可以达到11万美元,合人民币76万元。
Demo一出,大家纷纷尝试乐在其中,在饭香浓郁的评论区里异口同声地说“这不是合成的,这简直就是真的,但真的好贵啊”。
论文回顾
效果惊人也耗资巨大的BigGAN不是这两天才火的,一个多月前,当搭载BigGAN的双盲评审中的ICLR 2019论文现身,行家们就沸腾了:效果怎么就这么逼真了?
在计算机图像研究史上,BigGAN的效果比前人进步了一大截。比如在ImageNet上进行128×128分辨率的训练后,它的Inception Score(IS)得分166.3,是之前最佳得分52.52分3倍。
除了搞定128×128小图之外,BigGAN还能直接在256×256、512×512的ImageNet数据上训练,生成更让人信服的样本。
在论文Large Scale GAN Training for High Fidelity Natural Image Synthesis中,研究人员揭秘,BIgGAN的惊人效果背后,真的付出了金钱的代价。
因为不止是模型参数多,训练规模也是有GAN以来最大的。它的参数是前人的2-4倍,批次大小是前人的8倍。
研究人员对GAN架构做出了两处改动适应大规模训练的不稳定性,比如对判别器的通道类型做改动,让每个模块第一个卷积层里的滤波器数量和输出滤波器相等,比如生成器G用了单个共享类嵌入,为BatchNorm层生成每个样本的增益和偏差。
△ 生成器和鉴别器架构
评审结果
BigGAN评审结果已经放出,获得了三位评审8分、7分和10分的评价,目前以8.45分位居ICLR2019两百篇论文的前5位。
在OpenReview上,审稿人对这篇论文有以下几点类似的看法:
1)BigGAN在大规模数据集、大尺寸文件上有不错的表现。
2)附录中提到了一些负面的结果,这给未来的改进工作提供了帮助。
3)文章对大型模型的截断技巧缺乏清晰的、易于理解的讨论。
3位评审者评价如下:
评审1:
评分:8,接受论文的top 50%,明确接受。
信心:4,审稿人有信心,但并不绝对肯定评估是正确的。
本文提出了一套用于训练大规模GAN的技巧,并获得了高分辨率图像的最新结果。
优点:
-提出的技术直观且目的非常明确
-这项工作的一大优点是,作者试图通过训练速度和性能改进来“量化”提出的每一种技术
-探测崩溃的详细分析,提高了大规模GAN的稳定性
-试验结果令人印象深刻
缺点:
-所需的计算预算资源巨大。BigGAN原论文提到的模型使用了128-256个TPU,严重限制了结果的可重复性。
总结:
论文写得很好,思想很合理,结果非常引人注目。这是一篇很好的论文,强烈建议接受。
评审2:
评分:7,好文章,接受。
信心:3,评审员对评估是否正确非常有信心。
作者提出提出了将GAN扩展到复杂数据集(如ImageNet)方法的实证研究,用于类条件图像生成。
他们首先根据最近提出的GAN技术构建并描述一个强大的baseline,推动大型数据集的性能,获得了领先的IS / FID分数,以及令人印象深刻的视觉效果。
作者提出了一个简单的截断技巧来控制保真度/方差,它本身很有趣,但不能随着体系结构进行扩展。作者进一步提出了基于正交化的正则化来缓解这个问题。
作者还进行了大规模训练崩溃的调查,根据收集的经验证据研究了一些正则化方案。
优点:
-文章提供了大量关于GAN稳定性和在大规模训练数据集下性能的深入见解。这对于在复杂数据集上使用GAN、并且可以访问大量计算资源的任何人都应该是有用的。
-尽管GAN的常用评估指标仍然不够充分,但作者获得的量化表现远远超出以前的工作,这似乎确实与显著的视觉效果相关。
-基线增加修改被很好地描述和清晰地解释。附录在这方面也具有重要价值。
缺点:
-讨论有时缺乏深度。
我不清楚为什么一些较大的模型不适合截断。
作者提出了更宽的网络如何表现最佳,以及网络的深度如何降低性能。这一点同样缺乏讨论,作者似乎并没有试图理解为什么会出现这样的现象。
我认为应该更努力去理解和解释为什么会出现其中一些现象,它可以更容易地指引未来的工作。
-第3.1节:“在表1中,我们观察到没有正交正则化,只有16%的模型适合截断,而正交正则化则为60%。”对于我来说,这一点并不是特别清楚。这是读者应该从表1中理解的东西吗?
-我质疑正文和附录中选择的部分。我非常感谢正文和附录中报告的负面结果,这具有重要价值。
然而,这篇文章对我来说主要是一个详细的实证调查和大规模高性能GAN的介绍,我可能会与想要解决类似问题的同事分享这一点。
在这种情况下,如果未来的读者仅限于文本,我认为提供附录B和C中的一些内容比拥有超过一整页的稳定性调查和未完成的尝试技巧更有价值。
总结:
文章对GAN可扩展性的研究取得成功,即使在不牺牲ImageNet的高性能的情况下无法稳定训练令人失望。对以前的SOTA的改进绝对是重要的。这项工作展示了复杂数据集的现代GAN架构,可以成为未来工作的坚实基础。
但是我认为文章可以而且应该通过对表现行为进行更详细的分析和讨论,来改进论文,以便进一步指导和激励未来的工作。
我也很想看到所提出的技术应用于更简单的数据集。这对于计算能力较低且与CelebA类似的人会有用吗?
评审3:
评级:10,接受论文的top 5%,开创性论文
信心:4,审稿人有信心,但并不绝对肯定评估是正确的
本文的核心新元素是截断技巧:在训练时,输入z从正态分布中采样,但在测试时,使用截断的正态分布:当z的元素的大小高于某个阈值时,将被重新采样。如实验所示,该阈值的变化导致FD和IS的变化。
文章包含负面结果和详细的参数清扫,这一点也很好。
总结:
这是一项非常好的工作,取得了令人瞩目的成果,在图像生成领域取得了巨大的进步。