不知道自己未来的老婆 or 老公长什么样?来,我们先用 AI 预测出一个。
单身多年的你,是否曾幻想另一半的模样?最近,有这样一个开源项目在深度学习社区火了起来——通过神经网络生成你另一半的相貌。想知道自己会和什么样的人在一起吗?已有网友尝试了生成效果。
项目地址:https://github.com/irfanICMLL/CoupleGenerator
作者自己介绍,这是一个自 2017 年便开源了的项目,当时使用的是 TensorFlow,不过最近项目代码改成了 PyTorch。
得到对象只需 8800 步训练
项目使用了一百多位新婚夫妇的结婚照片,图像是通过爬虫从百度上爬取下来的。
这些结婚照都有着统一的模板:喜庆而单一的红色背景,清晰的人脸和五官,对模型训练比较友好和方便。
训练样本之一。爬取方法:https://blog.csdn.net/qq_27879381/article/details/65015280#comments
在模型构建和训练上,项目采用了 VGG 作为骨架网络学习图像特征。VGG 是一种常见的神经网络架构,发布于 2014 年,作者是 Karen Simonyan 和 Andrew Zisserman,该网络表明堆叠多个层是提升计算机视觉性能的关键因素。VGGNet 包含 16 或 19 层,主要由小型的 3×3 卷积操作和 2×2 池化操作组成。
VGG 的优点在于,堆叠多个小的卷积核而不使用池化操作可以增加网络的表征深度,同时限制参数的数量。例如,通过堆叠 3 个 3×3 卷积层而不是使用单个的 7×7 层,可以克服一些限制。
首先,这样做组合了三个非线性函数,而不只是一个,使得决策函数更有判别力和表征能力。第二,参数量减少了 81%,而感受野保持不变。另外,小卷积核的使用也扮演了正则化器的角色,并提高了不同卷积核的有效性。
在生成结果的过程中,模型使用 pix2pix 的方式。Pix2pix 是一种基于 GAN 架构的风格转换模型,来自论文《Image-to-Image Translation with Conditional Adversarial NetWorks》,作者包括朱俊彦等,论文在 CVPR 2017 发表后,已有多种框架的实现。
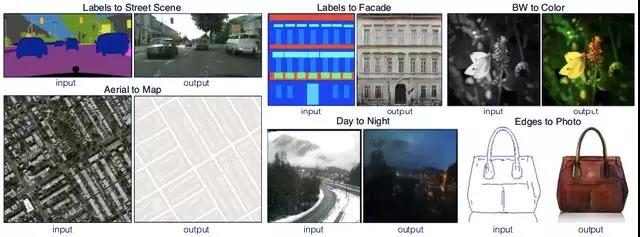
Pix2pix 使用成对的图片数据,学习从一个图像到另一个图像的转换方式,并生成能够以假乱真的图像。
使用 pix2pix 实现不同风格和用途图像的互相转换。
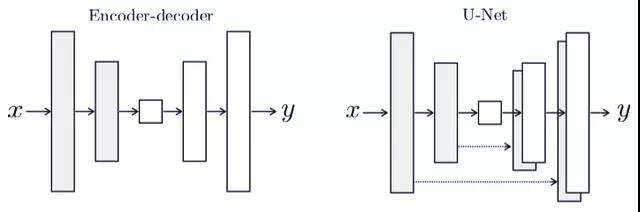
在 Pix2pix 中,生成器采用 encoder-decoder 或 U-Net 的架构。
两种 Pix2pix 的生成器架构。
那么,应该怎么使用这个项目呢?
使用方法
在项目中,作者提供了一些内容,包括:
CKPT 模型文件:
https://cloudstor.aarnet.edu.au/plus/s/YHDWgez1g3RFc6o
VGG 权重文件:
https://github.com/machrisaa/tensorflow-vgg
训练数据:
https://cloudstor.aarnet.edu.au/plus/s/VWZJaWfbla3kFch
在使用的过程中,你需要下载 VGG 权重文件和训练数据,下载代码到运行环境中并运行 autotest.sh 文件。
效果
在训练 8800 步后,模型对给定的图片提供了生成结果,如下所示:
考虑到训练数据并不算多,生成图像的质量还有提高的空间。此外我们可以注意到,模型也学习了一些有趣的特征,比如右上角原始图像中有结婚证,则生成的图像中也保留了结婚证这一要素。
项目作者介绍
这个项目的作者是一位非常漂亮的小姐姐,目前在澳大利亚阿德莱德大学攻读计算机科学博士学位,师从沈春华教授。
Yifan Liu。
Liu 同学本科和硕士就读于北京航空航天大学自动化科学与电气工程学院,曾获得 2016 年北京市优秀毕业生。在 2018 年 11 月进入阿德莱德大学攻读博士学位之前,她曾是微软亚研高级研究员、2018 年 ACM 杰出会员王井东教授的访问学生。
Liu 的主要研究方向是神经计算、模式识别等领域,包括图像语义分割等。在学术研究方面,2017 至 2019 年,她作为一作或其他作者的多篇论文被 CVPR、ICCV、PAKDD、IEA/AIE、PACLING 等国际学术会议接收,有一些为 Oral 论文。
这是她的个人主页:https://irfanicmll.github.io/
实测效果怎么样
为了试一试项目的效果,我们也下载了项目的预训练权重(迭代 8800 次)以及 VGG16 的预训练权重。因为数据集非常小,我们先用项目中的数据试一试效果。如下所示我们用项目 datasets 目录下的图像做测试,其中左侧为两组输入图像,右侧为输出图像。从生成结果来看,不论性别,另一半的相貌总是能够被生成出来的,还进行了一点磨皮。
如果我们只给一张人像呢?现在看起来,模型的生成规则是输出输入图像中左侧的人像,如果只输入一张人像的效果可能会变差。为了验证这个想法,我们将上述两张图都截成一个单一人像并输入模型。正如所料,现在生成效果不太好。如下所示左侧为两组输入样本,右侧为输出效果。
如果数据不从测试数据集中获得呢?在默认输入规则为夫妻合照的情况下,我们再次进行了新的尝试。通过输入不在数据集中的夫妻人像样本,并检查模型的生成效果。如下图所示,左侧为输入图像,右侧为输出结果,生成的图像较难识别。夫妻图像来自网络搜索结果。
诚然,利用现有数据预测未来对象的相貌这种想法是很不错的,但是由于数据量太小,模型的泛化能力还没有达到应有的要求。总的来说,单身狗还不能光靠这个生成一张自己对象的照片。
项目作者也表示,数据量比较少,效果也不太好,但是依然欢迎大家使用代码和数据进行进一步的训练,我们也会进一步关注项目的进展。